Adaptable Anatomical Models for Realistic Bone Motion Reconstruction
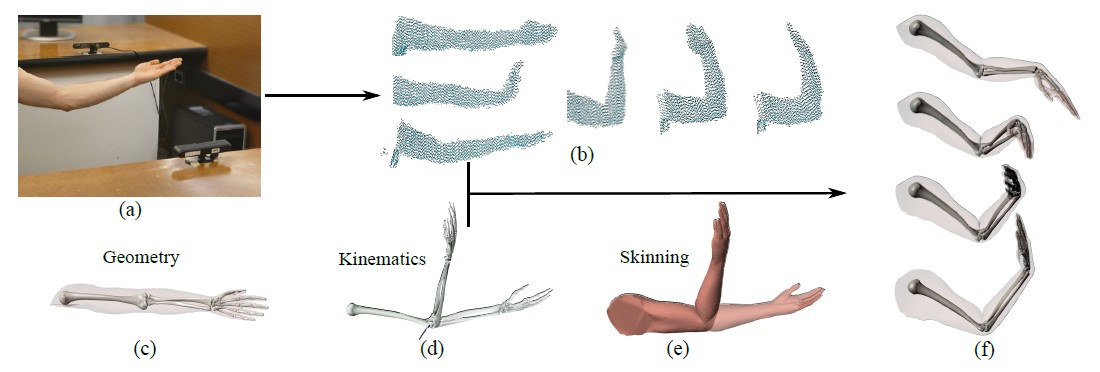 |
AbstractWe present a system to reconstruct subject-specific anatomy models while relying only on exterior measurements represented by point clouds. Our model combines geometry, kinematics, and skin deformations (skinning). This joint model can be adapted to different individuals without breaking its functionality, i.e., the bones and the skin remain well-articulated after the adaptation.We propose an optimization algorithm which learns the subject-specific (anthropometric) parameters from input point clouds captured using commodity depth cameras. The resulting personalized models can be used to reconstruct motion of human subjects. We validate our approach for upper and lower limbs, using both synthetic data and recordings of three different human subjects. Our reconstructed bone motion is comparable to results obtained by optical motion capture (Vicon) combined with anatomically-based inverse kinematics (OpenSIM). We demonstrate that our adapted models better preserve the joint structure than previous methods such as OpenSIM or Anatomy Transfer. PublicationLifeng Zhu, Xiaoyan Hu, Ladislav Kavan. Adaptable Anatomical Models for Realistic Bone Motion Reconstruction. Computer Graphics Forum 34(2) [Proceedings of Eurographics], 2015. Links and DownloadsAcknowledgementsWe are indebted to Marianne Augustine, Norm Badler, Scott Delp, Bryan Dunham, James Gee, Alec Jacobson, Diego Jaramillo, Kang Li, Dimitris Metaxas, Benedict Brown, Aline Normoyle, James O’Brien, Saba Pascha, Mark Pauly, Eftychios Sifakis, Sofien Bouaziz, Leonid Sigal, Daniel Sykora, C.J. Taylor, Eo Trueblood, and Tomas Vondrak for numerous insightful discussions. Our special thanks belong to Spiro Metaxas, Vimanyu Jain, Nathan Marshak, and Sibi Vijayakumar for help with acquisition, data processing, and video editing. Aline Normoyle and Brittany Binler helped to narrate the accompanying video. This research has been supported by NSF CAREER Award IIS-1350330. Xiaoyan Hu has been partially supported by NSFC (No.61103086 and 61170186). |