|
The problem that this chapter addresses is that low-level system activity in a general-purpose operating system can adversely affect the predictable scheduling of real-time applications. In effect, the OS “steals” time from the application that is currently scheduled. Two schedulers that provide augmented CPU reservations are described and evaluated; they increase the predictability of real-time applications in the presence of stolen time
To strengthen the case for augmented CPU reservations, we have performed a study of the amount of CPU time that can be stolen by a number of different device drivers in real-time versions of Linux and Windows 2000. We learned, for example, that the default configuration of the IDE disk driver in Linux can steal close to 50% of a CPU reservation.
Augmented reservations are just one way of coping with stolen time. Section 11.9 presents a comparison and evaluation of different methods of coping with stolen time.
The work on guarantees that was described in Chapter 5 assumed that stolen time due to operating system overhead does not interfere with guarantees. This assumption is justified because most operating system events such as scheduling decisions and interrupts take on the order of microseconds or tens of microseconds, while multimedia and other soft real-time applications generally require processing on a granularity of milliseconds or tens of milliseconds. Furthermore, due to caching, branch prediction, pipelining, and other effects, it can be very difficult to establish a tight bound on the worst-case execution time for a piece of code. It is assumed that applications will have to overestimate their CPU requirements slightly, and that stolen time can be “hidden” in the slack time.
In certain cases--the ones that we focus on in this chapter--stolen time significantly interferes with applications and it must be taken into account if deadlines are to be met. Although it may be possible to revise the definitions of guarantees to be probabilistic in order to reflect the possibility of stolen time, this would complicate analysis of scheduler composition (even in the common case where there is little stolen time), and it is not clear that stolen time can be bounded or that it follows any standard probability distribution.
The approach taken in this chapter is to leave the integration of stolen time into the guarantee framework as future work. Augmented CPU reservations, then, are not a kind of guarantee that is different from the reservation guarantees presented in Chapter 5 . Rather, they are the same type of guarantee, but they allow an assumption made by the reservation scheduler, that there is a negligibly small amount of stolen time, to be relaxed.
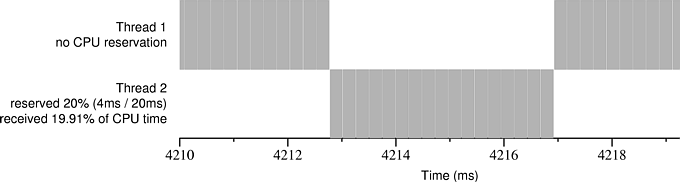
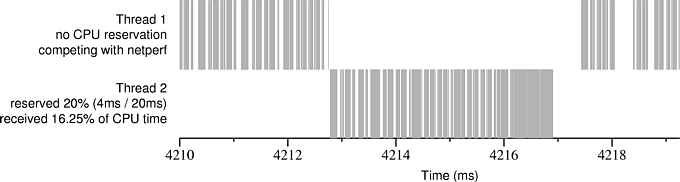
Figures 11.1 and 11.2illustrate the effects of stolen time. Each figure shows an actual execution trace of a CPU reservation that was granted by Rez. In both figures Thread 2 has been granted a CPU reservation of 4 ms / 20 ms. In the center of each figure is a single 4 ms block of time that Rez allocated to Thread 2. Each millisecond appears to be divided into roughly four chunks because the clock interrupt handler periodically steals time from the running application--we ran the clock at 4096 Hz in order to approximate precisely scheduled interrupts, which are not available in Windows 2000.
|
|
In Figure 11.1 our test application has the machine to itself, and Thread 1 uses up all CPU time not reserved by Thread 2. In Figure 11.2, the test application is running concurrently with an instance of Netperf, a network bandwidth measurement application that is receiving data from another machine over 100 Mbps Ethernet. Thread 1, which is running at low priority, gets less CPU time than it did in Figure 11.1 because it is sharing the processor with Netperf. However, Netperf does not get to run during the block of time reserved for Thread 2. There are gaps in the CPU time received by Thread 2 because the machine continues to receive data even when the Netperf application is not being scheduled, and the kernel steals time from Thread 2 to process this data. This stolen time causes Thread 2 to receive only about 82% of the CPU time that it reserved. A real-time application running under these circumstances will have difficulty meeting its deadlines.
The root of the problem is that although Rez ensures that Thread 2 will be scheduled for a 4 ms interval (or for several intervals adding up to 4 ms) during each 20 ms period, it is not necessarily the case that Thread 2 will get to execute for the entire 4 ms--stolen time is invisible to the thread scheduler. To address this problem we have designed and implemented two novel schedulers, Rez-C and Rez-FB, that provide augmented CPU reservations--they actively measure stolen time and counteract its effects, allowing deadlines to be met even when the OS steals a significant amount of CPU time from a real-time application. Rez-C gives applications the opportunity to “catch up” after time has been stolen from them, and Rez-FB uses a feedback loop to ensure that in the steady state applications actually receive the amount of CPU time that they have reserved.
We define stolen time to be CPU time spent doing something other than running the currently scheduled application or performing services on its behalf. Time is stolen because bottom-half device driver processing in general-purpose operating systems is assigned a statically higher priority than any application processing, and because this time is not accounted for properly: it is “charged” to the application that happens to be running when a device needs service.
Bottom-half processing occurs in the context of interrupts and deferred procedure calls. Interrupts are hardware-supported high-priority routines invoked when an external device requests service. Deferred procedure calls (DPCs), which are analogous to bottom-half handlers in Linux and other Unix variants, were designed to give device drivers and other parts of the kernel access to high-priority, lightweight asynchronous processing outside of interrupt context [77, pp. 107-111]. DPCs were identified as potential problems for real-time tasks on Windows NT by Ramamritham et al. [72].
In effect, Windows 2000 and similarly structured operating systems contain not one but three schedulers. Interrupts take precedence over all other processing and are scheduled by a fixed-priority preemptive scheduler that is implemented in hardware. DPCs take precedence over all thread processing and are scheduled by a simple FIFO scheduler. Finally, applications are scheduled at the lowest priority by the OS thread scheduler (which is normally thought of as “the scheduler”).
Rez, the reservation scheduler that we described in Section 9.3.2 , is the basis for the augmented reservation schedulers presented in this chapter. Rez suffers from reduced predictability because bottom-half mechanisms in Windows 2000 can steal time from real-time applications. Our approach to improving predictability is called augmented reservations. The basis of this approach is to give the reservation scheduler access to fine-grained accounting information indicating how long the kernel spends running DPCs, allowing it to react accordingly. To this end we implemented two additional versions of the Rez scheduler called Rez-C and Rez-FB; they are described in Sections 11.5.2 and 11.5.3, respectively.
The scheduling hierarchy that we used for all Windows 2000 experiments reported here runs one of the variants of Rez at the highest priority, and runs a priority-based timesharing scheduler when Rez has no threads to run. Rez has an admission controller that rejects any requests for reservations that would cause the cumulative CPU requirements over all reservations to exceed a fixed fraction of the capacity of the CPU. To prevent reservations from starving the timesharing scheduler this parameter can be set to a value less than 1.0. We currently use 0.85; the value chosen should reflect the relative importances of the time-sharing and real-time classes of applications on a particular system.
Once a real-time scheduling abstraction such as CPU reservations has been implemented within a general-purpose operating system, the ways to increase predictability with respect to stolen time form a continuum:
The first option has been recently explored by Jones and Saroiu [41] in the context of a software modem driver. Jeffay et al. [34] chose the third option: they modified FreeBSD to perform proportional-share scheduling of network protocol processing. Our work is based on the second option. There are advantages and disadvantages to each approach, and we believe that there are situations in which each of them is appropriate. We will compare the approaches in detail in Section 11.9.
Of the two sources of stolen time in Windows 2000, interrupts and DPCs, we have instrumented only DPCs. Although it would be straightforward to instrument hardware interrupt handlers as well, the time spent in DPCs serves as a useful approximation of the true amount of stolen time because interrupt handlers in Windows 2000 were designed to run very quickly: they perform critical processing and then enqueue a DPC to perform any additional work.
To instrument DPCs we added code to the beginning and end of the dispatch interrupt handler (a software interrupt handler that dequeues and runs DPCs) to query the Pentium timestamp counter (using the rdtsc instruction) which returns the number of cycles since the machine was turned on. By taking the difference between these values the system can accurately keep track of the amount of time spent running DPCs.
The interface to stolen time accounting is the GetStolen() function, which is available to code running in the Windows 2000 kernel; it returns the amount of stolen time since it was last called. In other words, it atomically reads and zeros the stolen time counter.
Rez-C gives threads the opportunity to catch up when they have had time stolen from them. It does this by deducting from budgets only the actual amount of CPU time that threads have received, rather than deducting the length of the time interval that they were nominally scheduled for, which may include stolen time. For example, if a thread with a reservation of 4 ms / 20 ms is runnable and will have the earliest deadline during the next 4 ms, Rez-C schedules the thread and arranges to regain control of the CPU in 4 ms using a timer. When the timer expires, Rez-C checks how much time was stolen during the 4 ms interval using the GetStolen() function. If 1.2 ms were stolen, then Rez-C deducts 2.8 ms from the thread’s budget. If the thread still has the earliest deadline, Rez-C arranges to wake itself up in 1.2 ms and allows the thread to keep running.1
Rez-C uses accounting information about stolen time at a low level, bypassing the admission controller. When there is not sufficient slack in the schedule, allowing a thread to catch up may cause other threads with reservations to miss their deadlines or applications in the timesharing class to be starved. These deficiencies motivated us to design Rez-FB.
Our second strategy for coping with stolen time assumes that the amount of stolen time in the near future will be similar to what it was in the recent past. It uses a feedback loop to minimize the difference between the amount of CPU time that each application attempted to reserve and the amount of CPU time that it actually receives. There is an instance of the feedback controller for each thread that has a CPU reservation. The parameters and variables used by the feedback controller are:
The feedback equation, which is evaluated for each reservation each time its period starts, is:
In other words, at the beginning of a reservation’s period the amount of CPU time requested by Rez-FB on behalf of the application is adjusted to compensate for the difference between the desired and actual amounts of CPU time during the previous period. The gain helps prevent overshooting and can be used to change how aggressively the controller reacts to changing amounts of stolen time.
Because Rez-FB applies accounting information to reservation amounts rather than budgets, it does not bypass the admission controller. Therefore, Rez-FB will not allow threads with CPU reservations to interfere with each other, or with time-sharing applications. On the other hand, Rez-FB reacts more slowly to stolen time than Rez-C, potentially causing applications to miss more deadlines when the amount of stolen time varies on a short time scale. The feedback controller currently used by Rez-FB is a special case of a PID (Proportional-Integral-Derivative) controller that contains only the integral term. In the future we may attempt to improve Rez-FB’s response to changes in the amount of stolen time using more sophisticated controllers that have proportional and derivative terms as well.
In the next two sections we will evaluate and compare Rez-C and Rez-FB according to the following criteria:
The application scenarios that we will consider include the following elements: a general-purpose operating system, Windows 2000, that has been extended with Rez (as a control), Rez-C, or Rez-FB; a soft real-time application that uses a reservation to meet its periodic CPU requirements; and, a background workload that causes the OS to steal time from the real-time application.
The soft real-time application used in our experiments is a synthetic test application. The important qualities of this application are: the ability to create multiple threads at different priorities, with optional CPU reservations; the ability to detect stolen time by measuring exactly when these threads are scheduled; and, for threads with reservations, the ability to determine if and when deadlines are missed.
To this end we started with a test application that was originally developed for the Rialto operating system at Microsoft Research and later ported to Rialto/NT [37]. For the work reported here we ported it to TimeSys Linux/RT and Windows 2000 + Rez, and gave it the capacity to detect deadline misses for threads with ongoing CPU reservations.
Rather than using the CPU accounting provided by
the operating system2 our
test application repeatedly polls the Pentium timestamp counter.
When the difference between two successive reads is longer than 2.2
![]() s, time is assumed to have been stolen from the
application between the two reads. This number was experimentally
determined to be significantly longer than the usual time between
successive reads of the timestamp counter and significantly shorter
than common stolen time intervals. The duration of the stolen time
interval is taken to be the difference between the two timer values
minus the average time spent on the code path between timer reads
(550 ns). We believe that this provides a highly accurate measure
of the actual CPU time received by the application.
s, time is assumed to have been stolen from the
application between the two reads. This number was experimentally
determined to be significantly longer than the usual time between
successive reads of the timestamp counter and significantly shorter
than common stolen time intervals. The duration of the stolen time
interval is taken to be the difference between the two timer values
minus the average time spent on the code path between timer reads
(550 ns). We believe that this provides a highly accurate measure
of the actual CPU time received by the application.
Threads with reservations repeatedly check if the amount of wall clock time that has elapsed since the reservation was granted has passed a multiple of the reservation period. Each time this happens (in other words, each time a period ends) they register a deadline hit if at least the reserved amount of CPU time has been received during that period, or a deadline miss otherwise.
The workload used is an incoming TCP stream over 100 Mbps Ethernet (we characterize other sources of stolen time in Section 11.8 ). We chose this workload because it is entirely plausible that a desktop computer may be in the middle of a real-time task such as playing a game or performing voice recognition when high-bandwidth data (such as a file transfer) arrives over a home or office network.
To actually transfer data we used the default mode of Netperf [29] version 2.1, which establishes a TCP connection between two machines and transfers data over it as rapidly as possible.
Our test machine was a dual 500 MHz Pentium III
with 256 MB of RAM. It ran in uniprocessor mode for all
experiments. It was connected to the network using an Intel
EtherExpress Pro/100B PCI Ethernet adapter. For all experiments in
this section the machine ran one of our modified Windows 2000
kernels, and had a timer interrupt period (and therefore a minimum
enforceable scheduling granularity) of 244 ![]() s.
s.
Unless otherwise stated, all data points in this section and in Section 11.8 are averages of ten 10-second runs. Confidence intervals were calculated at 95%.
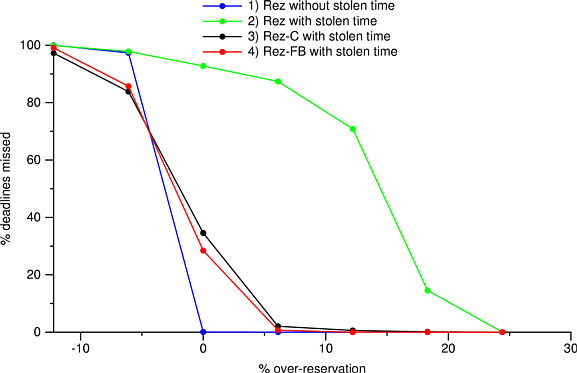
Figure 11.3 shows the number of deadline misses detected by our test application with a reservation of 4 ms / 20 ms under four different conditions:
To meet each deadline, the test application needed to receive 4 ms of CPU time during a 20 ms period. In order to demonstrate the effect of statically over-reserving as a hedge against stolen time, for each of the four conditions we had Rez actually reserve more or less than the 4 ms that was requested. So, if Rez were set to over-reserve by 50%, it would actually reserve 6 ms / 20 ms when requested to reserve 4 ms / 20 ms.
Line 1 shows that on an idle machine, any amount of under-reservation will cause most deadlines to be missed, and that no deadlines are missed by the test application when it reserves at least the required amount of CPU time. This control shows that Rez is implementing CPU reservations correctly.
Line 2 (the rightmost line on the graph) illustrates the effect of time stolen by network receive processing. To avoid missing deadlines, Rez must over-reserve by about 24%. This is quite a large amount, and would not prevent the application from missing deadlines in the case that several drivers steal time simultaneously. In Section 11.9.1 we will argue that pessimistic over-reservation is not a good general solution to the problem of deadline misses due to stolen time.
Lines 3 and 4 are very similar, and show that both Rez-C and Rez-FB increase the predictability of CPU reservations when the OS is stealing time from applications. Notice that a small amount of over-reservation (about 6%) is required before the percentage of missed deadlines goes to nearly zero. Some deadlines are missed in the 0% over-reservation case because we only instrumented DPCs, and not hardware interrupt handlers.
We calculated confidence intervals for the data points in Figure 11.3 but omitted them from the graph because they were visually distracting. The 95% confidence interval was always within 3.4% of the means reported here, and was significantly less than that for most of the data points.
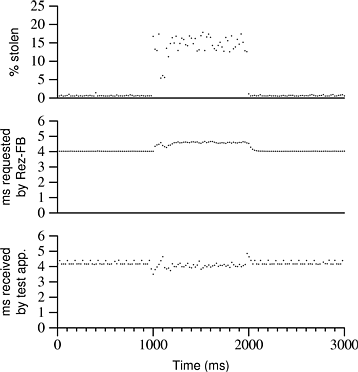
Rez-C is very simple and retains no information about stolen time between periods of a reservation. However, as we described in Section 11.5.3 , Rez-FB uses a feedback loop that compares its current performance to performance in the previous period. This raises questions about stability, overshoot, and reaction time. The intuition behind its feedback loop is straightforward and we believe that Rez-FB is stable and predictable, and that it will quickly converge on the correct amount of CPU time to allocate. However, we have performed an experiment under changing load in order to test this hypothesis. Figure 11.4 shows the response of Rez-FB to a 1-second burst of network traffic, which happens between times 1000 and 2000. The test application has created a single thread with a CPU reservation of 4 ms / 20 ms. So, R = 4.0 ms. This graph contains no confidence intervals since the data come from a single execution. Each point on the graph represents a single 20 ms period.
|
The top graph in Figure 11.4 shows the amount of stolen time reported to Rez-FB by each call to GetStolen(), expressed as a percentage of 4 ms. It shows that there is a small base amount of time stolen by background system activity, and that stolen time increases dramatically during network activity. This is exactly what we would expect. The middle graph shows Ct, the amount of CPU time requested by Rez-FB during each period. As expected, Rez-FB requests more CPU time when more time is being stolen by the kernel. Although the amount of stolen time at the start of Netperf’s run is noisy (probably due to TCP slow start and other factors), its finish is abrupt and around time 2000 Ct drops from its elevated level back to about 4.0, cushioned by the gain G. Although we tried several different values for G, all experiments reported here used a value of 0.5. We did not look into the sensitivity of this parameter in detail, but values between 0.5 and 1 appeared to produce about the same number of missed deadlines.
The bottom graph shows Pt, the
actual amount of CPU time received by our test application during
each period. While the machine is quiet (in ranges 0-1000 and
2000-3000) the values of Pt are quantized because the scheduling
enforcement granularity is limited to 244 ![]() s. A deadline is missed
whenever Pt is below 4.0; this happened 22 times during
the test. This is due to unaccounted stolen time from the network
interrupt handler and also to lag in the feedback loop. While
missing 22 deadlines may be a problem for some applications, this
is significantly better than missing most of the 500 deadlines
between times 1000 and 2000, as would have happened with Rez under
the same conditions. To support applications that cannot tolerate a
few missed deadlines, the system would need to instrument stolen
time more comprehensively or statically over-reserve by a small
amount.
s. A deadline is missed
whenever Pt is below 4.0; this happened 22 times during
the test. This is due to unaccounted stolen time from the network
interrupt handler and also to lag in the feedback loop. While
missing 22 deadlines may be a problem for some applications, this
is significantly better than missing most of the 500 deadlines
between times 1000 and 2000, as would have happened with Rez under
the same conditions. To support applications that cannot tolerate a
few missed deadlines, the system would need to instrument stolen
time more comprehensively or statically over-reserve by a small
amount.
Both Rez-C and Rez-FB add very little overhead to the scheduler. The overhead of instrumenting DPCs (incurred each time the kernel drains the DPC queue) is twice the time taken to read the Pentium timestamp counter and write its result to memory, plus the time taken by a few arithmetic operations. Similarly, the overhead of the GetStolen() call is the time taken to run a handful of instructions.
To verify that the augmented reservation schedulers add little overhead we measured how much CPU time was lost to a reservation running under Rez-C and Rez-FB as compared to the basic Windows 2000 + Rez. This revealed that Rez-C adds 0.012%±0.0028 overhead and Rez-FB adds 0.017%±0.0024 overhead. We would have been tempted to assume that these differences were noise but the confidence intervals indicate that they are robust.
As we mentioned in Section 11.5.2, Rez-C has two main problems. First, its catchup mechanism can cause threads with CPU reservations to miss their deadlines, and second, when the total amount of reserved time plus the total amount of stolen time exceeds the capacity of the processor, timesharing threads will be starved. The first problem is inherent in the design of Rez-C, but the second could be helped by giving a CPU reservation to the entire class of time-sharing applications (this is easy in a system that supports hierarchical schedulers). While this would not prevent overload, giving the timesharing scheduler a reservation would ensure that it is not completely starved because there would be at least some times at which it had the earliest deadline.
In Rez, Rez-C, and Rez-FB it would be a good idea to give the timesharing scheduler a reservation even when there is no risk of overload, to ensure that timesharing applications are scheduled often enough that their response to user input appears to be smooth rather than jumpy. For example, a real-time application with a reservation of 0.5 s / 1 s would currently make the system difficult to use by allowing timesharing applications (such as the user interface) to run only every half-second. A CPU reservation (of 7 ms / 50 ms, for example) for the timesharing scheduler would keep non-real-time applications responsive to user input. In other words, humans introduce soft deadlines into the system; missing these deadlines will result in bored or irritated users.
Clearly, if timesharing applications were given a reservation we would want them to be able to use idle time in the schedule in addition to their reserved time. While this would not be difficult to implement, Rez currently does not allow a thread (or in this case, a collection of threads) with a CPU reservation to use more processor time than was reserved. Some reservation schedulers, such as the one in the portable resource kernel [68], have the ability to make CPU reservations either hard, guaranteeing both a minimum and maximum execution rate, or soft, guaranteeing only a minimum execution rate for applications that can make use of extra CPU time. This is a useful specialization, and implementing it in Rez, Rez-C, and Rez-FB is part of our future plans.
We have seen that Rez-C does not gracefully handle overload caused by stolen time. Rez-FB is better in this respect: it does not allow applications with CPU reservations to interfere with each other or with timesharing applications. However, overload in Rez-FB raises policy issues. Recall that overload in Rez-FB can be induced either by stolen time or by genuine application requests. Although it currently treats these cases identically (by rejecting all requests that would make system load exceed a fixed percentage), a more sophisticated admission control policy may be desirable. For example, assume that an important application is having time stolen, causing Rez-FB to increase the amount of its reservation. If this request would result in overload, perhaps instead of rejecting it Rez-FB should revoke some CPU time from a less important application, or one that can tolerate missed deadlines. Clearly there are many policy decisions that could be made here; we have not explored them.
Neither Rez-C nor Rez-FB imposes additional cost on the developers of real-time applications. Developers should only notice reservations becoming more predictable while a machine is receiving asynchronous data.
Both of these schedulers were fairly easy to implement once the basic Rez scheduler was working. Because Rez-C and Rez-FB make use of existing abstractions (budgets and reservation amounts) they each required only about 40 lines of code to be added to the basic Rez scheduler. The code to instrument DPCs added about 50 lines of assembly code to Windows 2000’s dispatch interrupt handler.
We have shown that stolen time can cause tasks with CPU reservations granted by Rez to miss their deadlines. Rez-C and Rez-FB, on the other hand, allow applications to receive approximately the same scheduling behavior when time is being stolen from them as they do on an idle machine. Rez-C behaves poorly when subjected to overload caused by stolen time, but we do not yet have enough experience with it to know if this is a significant problem in practice. Of the three, Rez-FB appears to be the most promising: it works well and does not have the disadvantages of Rez-C.
In Figure 11.3 we showed that network activity can significantly increase the number of deadlines an application misses despite the CPU scheduler’s best efforts. In this section we provide additional motivation for augmented CPU reservations by presenting the results of a study of the amount of time that can be stolen by the Linux and Windows 2000 kernels when they receive asynchronous data from a number of different external devices. For the Linux tests we used TimeSys Linux/RT [86], which adds resource kernel functionality [68] such as CPU reservations and precise timer interrupts to Linux.
Our goal was not to compare the real-time performance of Linux/RT and Windows 2000 + Rez, but rather to shed light on the phenomenon of stolen time and to find out how much time can be stolen by the drivers for various devices on two completely different operating systems. Indeed, these results will generalize to any operating system that processes asynchronous data in high-priority, bottom-half contexts without proper accounting. As far as we know, these are the first published results of this type.
For Linux tests we used TimeSys Linux/RT version 1.1A, which is based on version 2.2.14 of the Linux kernel. All Linux tests ran on the same machine that ran all of our Windows 2000 tests (a dual 500 MHz Pentium III booted in uniprocessor mode).
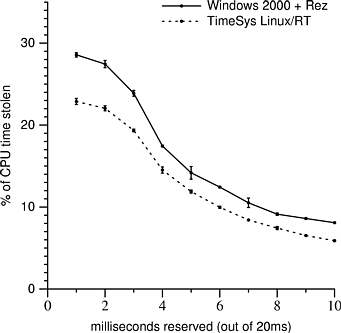
Figure 11.5 shows how the amount of time stolen from a CPU reservation by network receive processing changes with the amount of the reservation. The test application reserved between 1 ms and 10 ms out of 20 ms. The reason that the proportion of stolen time decreases as the size of the block of reserved time increases can be seen by looking closely at Figure 11.2: towards the end of the reserved block of time (after time 4216) there is little stolen time. This is because the Netperf application does not get to run during time reserved by the real-time application; therefore, kernel network buffers are not drained and packets are not acked, causing the sender to stop sending after a few milliseconds.
|
Although Figure 11.5 would appear to indicate that Linux processes incoming network data more efficiently than Windows 2000, no such inference should be drawn. The bandwidth received by our test machine while running Windows 2000 + Rez was around 93 Mbps and the bandwidth received while running Linux/RT was only about 81 Mbps. We do not have a good explanation for this, although we do know that the low network performance is not an artifact of Linux/RT--we observed the same low bandwidth while running the Linux kernel that shipped with Redhat 6.2. The sender and receiver were directly connected by a fast Ethernet switch and the machine sending the data was a 400 MHz Pentium II running Windows NT 4.0.
Table 11.1 shows the amount of time that was stolen from CPU reservations of 4 ms / 20 ms by OS kernels as they processed data coming from hard disks. We show measurements for both Linux/RT and Windows 2000 + Rez, for a SCSI and an IDE disk, and using both direct memory access (DMA) and programmed I/O (PIO) to move data to the host, when possible.
|
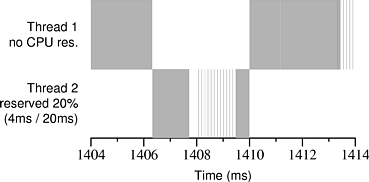
From this table we conclude that disk transfers that use DMA cause the OS to steal only a small amount of time from real-time applications (the confidence intervals indicate that the differences, though small, are real). However, even a slow disk can severely hurt real-time performance if its driver uses PIO: in our test it caused the Linux kernel to steal nearly half of the CPU time that a real-time application reserved. Therefore, it is imperative that real-time systems avoid using PIO-based drivers for medium- and high-speed devices. The large gap in Thread 2’s block of reserved time in Figure 11.6 illustrates the problem.
|
Unfortunately, Linux distributions continue to ship with PIO as the default data transfer mode for IDE disks. For example, we recently installed Redhat Linux 7.0 on a new machine equipped with a high-performance IDE disk. Due to overhead of PIO transfers, the machine was barely usable while large files were being read from the hard disk. Interactive performance improved dramatically when we turned on DMA for the hard disk using the hdparm command. Windows 2000 uses DMA by default for both SCSI and IDE disks.
Software-based modems contain minimal hardware support: they perform all signal processing in software on the main CPU. We measured time stolen by the same model of soft modem used by Jones et al. [41]. We agreed not to reveal the name of this modem, but it is based on an inexpensive chipset commonly found in commodity machines. Connecting the modem at 45333 bps (the highest our local lines would support) caused Windows 2000 + Rez to steal 9.87%±0.15 from a CPU reservation of 4 ms / 20 ms. We did not test the soft modem under Linux because driver support was not available.
Figure 11.5 showed that the percentage of CPU time stolen by the kernel while it processes incoming network data depends on the size of the reserved block of CPU time. This is because reserved time interferes with the user-level application that is causing data to arrive over the network. There is no analogous user-level application for a soft modem: even when no data is being transferred the CPU must still process samples received over the phone line. Therefore, the proportion of time stolen by the soft modem driver does not depend on the size of reserved blocks of CPU time.
As Jones et al. mention, software-based implementations of Digital Subscriber Line (DSL) will require large amounts of CPU time: 25% or more of a 600 MHz Pentium III. Obviously a soft DSL driver will steal significant amounts of CPU time from applications if its signal processing is performed in a bottom-half context.
Neither Linux nor Windows 2000 showed any measurable amount of stolen time when receiving 115 Kbps of data over a serial port; probably the amount of incoming data is simply too small to cause problems. We did not test for stolen time while machines received data over the parallel port, but we hypothesize that there would be little or none since parallel port data rates are also small.
While retrieving a large file over USB (the file was stored on a CompactFlash memory card), a reservation of 4 ms / 20 ms under Windows 2000 + Rez had 5.7%±0.032 of its reservation stolen. USB could become a much more serious source of stolen time in the future as USB 2.0 becomes popular--it is 40 times faster than USB 1.1 (480 Mbps instead of 12 Mbps). Finally, while we did not test Firewire devices, at 400 Mbps it is a potentially serious source of stolen time.
The simplest way to ensure that applications with CPU reservations receive the full amount of processor time that they reserved would be to have the reservation subsystem pessimistically over-reserve. That is, to have it silently increase the amount of each reservation by a fixed factor (like we did in Figure 11.3 ). The factor would be the sum of the worst-case CPU utilizations of all devices that may steal time from applications--this would include most network, SCSI, IDE, USB, and firewire devices. This approach would have the advantage of not requiring the instrumentation of stolen time that is necessary for Rez-C and Rez-FB to work.
Over-reservation is a practical way of dealing with overheads that can be easily bounded, such as the overhead caused by timer interrupts. More sophisticated analysis of this type is also possible: Jeffay and Stone [35] showed how to guarantee schedulability for a dynamic-priority system when time is stolen by interrupt handlers, although the worst-case execution time and maximum arrival rates of interrupts needed be known. Unfortunately, bounding the amount of time that may be stolen by all devices in a desktop computer running a general-purpose operating system is not easy or straightforward.
Calculating the worst-case amount of CPU time that even a single device/driver combination can steal is difficult: the calculation must be performed for every hardware combination because it depends on processor speed, memory latency and bandwidth, and I/O bus speed. It must test every useful mode of a driver.3 It also requires a test workload that correctly evokes worst-case response from the device driver; this will require multiple machines when testing network drivers. Furthermore, as we showed in Figure 11.5, for some drivers the amount of stolen time depends on the amount of the CPU reservation that they are stealing time from. We believe that these difficulties, multiplied by the hundreds of devices that must be supported by popular operating systems, imply that it is impractical to compute an accurate upper bound on the amount of time that bottom-half operating system processing may consume.
Systems programmers can manually reduce the amount of time stolen by a device driver by moving code from bottom-half contexts into scheduled contexts. For example, a DPC that moves a packet off of a network interface buffer could be converted into a very small DPC that awakens a worker thread that moves the packet. Jones et al. [41] have investigated the effects of moving CPU-intensive soft modem signal processing code from an interrupt handler first into a DPC, and then into thread context. In Section 11.8.3 we showed that a soft modem can steal close to 10% of a CPU reservation. In contrast, the amount of time stolen by the THR and RES versions of the soft modem driver described by Jones et al. would be small and most likely negligible.
The main problem with moving code out of time-stealing contexts is that to be successful overall, it requires fine-grained effort by a large number of driver developers, each of whom has an incentive to leave his or her code in a bottom-half context (that is more predictable, since bottom-half processing takes precedence over thread processing). This is an example of priority inflation, a social phenomenon that occurs when developers overestimate the priority at which their code should run. It happens because the motivations of driver developers (who want their device or subsystem to perform well) conflict with each other and with the motivations of system designers (who want overall predictability).
A number of recently designed operating systems can schedule device-driver activity. Because network interfaces are a principal source of asynchronous data and because TCP/IP stacks tend to involve copies and other CPU-intensive tasks, much of this work has focused on the scheduling of network protocol processing. Microkernels such as Mach [73] and Real-Time Mach [88] run device drivers and network protocols in user-level servers, allowing them to be scheduled normally. The Scout operating system [64] provides support for paths, channels through a layered communication system that can be explicitly scheduled. Nemesis [49] is a vertically-structured operating system that implements as much network processing as possible in shared libraries (rather than in shared servers or in a monolithic network stack) in order to simplify accounting and reduce crosstalk between applications. From our point of view the problem with these approaches is that most people are not interested in running a new OS: it is preferable to incrementally change an existing general-purpose OS, maintaining backwards application compatibility and approximately the same performance characteristics.
Relatively little work has been done on scheduling bottom-half activity in general-purpose operating systems. Druschel and Banga [19] have implemented scheduling and proper accounting (but not real-time scheduling) of network processing in SunOS to solve the problem of receiver livelock: the situation in which all CPU time is used by low-level network receive processing, preventing applications from receiving packets at all. Our work does not address this problem.
Jeffay et al. [34] have modified the scheduling and network protocol processing in FreeBSD to provide integrated real-time application and protocol scheduling. They implemented a number of specializations that made the network subsystem fair and predictable, even in the presence of flooding attacks. However, instead of preemptively scheduling bottom-half activity they rely on the fact that the particular bottom-half primitives that they schedule run for a known, bounded amount of time.
Although both Rez-C and Rez-FB increase the predictability of CPU reservations, neither of them allows us to give any absolute guarantee to applications because there is no upper bound on the amount of time that Windows 2000 spends in bottom-half contexts. For example, Jones and Regehr [38] describe a Windows NT device driver that would unexpectedly enqueue a DPC that took 18 ms to run. To bound this time would require scheduling bottom-half time, rather than just accounting for it.
Making DPCs in Windows 2000 or bottom-half
handlers in Linux preemptible would undoubtedly add some overhead:
it would be equivalent to giving DPCs (which are currently very
lightweight) a thread context. The median thread context switch
time (with no address space switch) on our test hardware running an
unmodified copy of Windows 2000 is 8.2 ![]() s. While our test machine
received data over 100 Mbps Ethernet it executed over 12,000 DPCs
per second. If each DPC resulted in two thread context switches
(one to a DPC thread and one back to the original thread), then
roughly 20% of the CPU would be used just to perform the context
switches. However, the reality is not likely to be this bad: DPCs
could be batched, amortizing the context switch time, and a clever
implementation of preemptible DPCs could probably run short DPCs
without a thread context, only elevating them to full thread status
in the (presumably uncommon) case where a DPC needs to be
preempted.
s. While our test machine
received data over 100 Mbps Ethernet it executed over 12,000 DPCs
per second. If each DPC resulted in two thread context switches
(one to a DPC thread and one back to the original thread), then
roughly 20% of the CPU would be used just to perform the context
switches. However, the reality is not likely to be this bad: DPCs
could be batched, amortizing the context switch time, and a clever
implementation of preemptible DPCs could probably run short DPCs
without a thread context, only elevating them to full thread status
in the (presumably uncommon) case where a DPC needs to be
preempted.
A good implementation of scheduled DPCs might reduce system throughput only slightly on consumer systems that do not move large amounts of data around. However, both Linux and Windows 2000 are commonly used as servers that are connected to many hard disks and several high-speed network interfaces. In these situations adding overhead to critical device driver code paths is not acceptable: high system throughput is critical. Therefore, it seems unlikely that mainstream versions of Windows 2000 or Linux will preemptively schedule DPCs and bottom-half handlers in the near future. Perhaps future consumer versions of these systems will do so.4
Finally, even if DPCs are scheduled interrupt handlers will still steal time from applications. Because interrupts are scheduled in hardware using a static-priority scheduler, it is not possible to schedule them in software using a different algorithm. The best way to prevent time stealing by interrupt handlers from becoming a serious obstacle to predictability is to ensure, through testing and code inspection, that device drivers perform as little work as possible in interrupt context.
The Rez algorithm itself is not novel: it is very similar to the constant utilization server developed by Deng et al. [18], the constant bandwidth server that Abeni and Buttazzo developed [2], and the Atropos scheduler developed for the Nemesis OS [49]. However, we believe the augmented extensions of Rez--Rez-C and Rez-FB--to be novel: previous implementations of CPU reservations in general-purpose operating systems have not addressed the problem of time stealing by bottom-half processing.
Although Rez and similar algorithms use budgets and EDF internally, many other implementations of CPU reservations are possible. These include the dynamic creation of complete schedules in Spring [81], the tree-based scheduling plan in Rialto [40] and Rialto/NT [37], and rate-monotonic scheduling in the Fixed-Priority Open Environment [45].
Rez-C and Rez-FB track an impediment to application progress, stolen time, and counteract it. A more aggressive approach would be to track application progress directly; it would then be possible to counteract all impediments to progress, not just the ones that we happen to measure. These include cache-related slowdown, memory cycle stealing by DMA, and actual changes in application requirements.
Steere et al. [83] track application
progress by giving a reservation scheduler access to the state of
buffer queues between the stages of pipeline-structured
applications. Lu et al. [56] have used feedback to attain
small numbers of missed deadlines at high system utilization when
task execution times are not known. Finally, a number of models
such as FARA by Ro![]() u et al. [75] have
used feedback about system load to select among different modes of
operation for adaptive real-time applications.
u et al. [75] have
used feedback about system load to select among different modes of
operation for adaptive real-time applications.
This chapter has presented and evaluated two novel schedulers that help provide increased predictability to applications even when low-level operating system activity “steals” time from them. Our conclusion is that augmented CPU reservations are a useful, lightweight mechanism for increasing the predictability of time-based schedulers.